
引言
可能因为今天出现热点,导致了 MQ 出现「消息堆积」,下游需要几天才能把消息消费完。为了避免这种情况,我们需要解决以下问题:
如何知道 MQ 出现了「消息堆积」?
如何定位并处理「消息堆积」问题?
如何避免「消息堆积」问题?
本文以 RocketMQ 为例
解决消息堆积思路
监控和告警
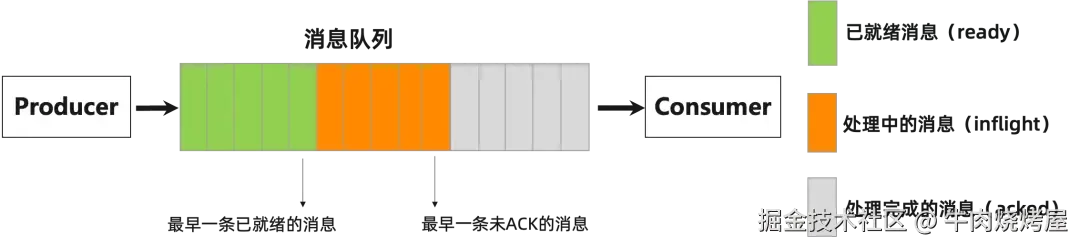
首先要确定的是,如何得知 MQ 出现了「消息堆积」?
消息总共有三种状态:已就绪、处理中、处理完毕
所以,可以使用「消息堆积量」(已就绪+ 处理中)来度量消费健康度,表示未处理完成的消息量。但存在缺点:
有误报或无法触发报警的问题
及时性的间接指标,不直观
比如,短时间内 MQ 接收到了大量消息,导致数量上达到了「报警阈值」。而实际下游消费速度足够给力,大量消息依旧可以在短时间内都消费完毕。此时不能认为出现了「消息堆积」问题
可以使用「延时时间」来度量消费健康度,可以涵盖所有业务场景:
已就绪消息排队时间:表示拉取消息及时度
消息处理延迟时间:表示业务处理完成及时度
比如,消息处理延迟时间超过了 5 秒,触发报警
对硬件资源的监控也是必要的
除了对 RocketMQ 消息堆积量和消息延迟时间监控外,还需要监控 RocketMQ 和消费者的 CPU、内存、磁盘、网络等资源。硬件资源直接影响性能和吞吐量
假设 RocketMQ 的带宽为 100MB,一条消息为 100KB,那么每秒只能发送 1000 条消息。如果此时下游的吞吐量为 1000,还想要继续加大消费吞吐量,优先考虑加大带宽
监控和告警
对于本地部署的 RocketMQ,可以通过 Prometheus + Grafana 对 MQ 进行监控和报警,具体可观测指标可以参考官方文档:RocketMQ Prometheus Exporter | RocketMQ
下图为阿里云云消息队列 RocketMQ 的监控和预警
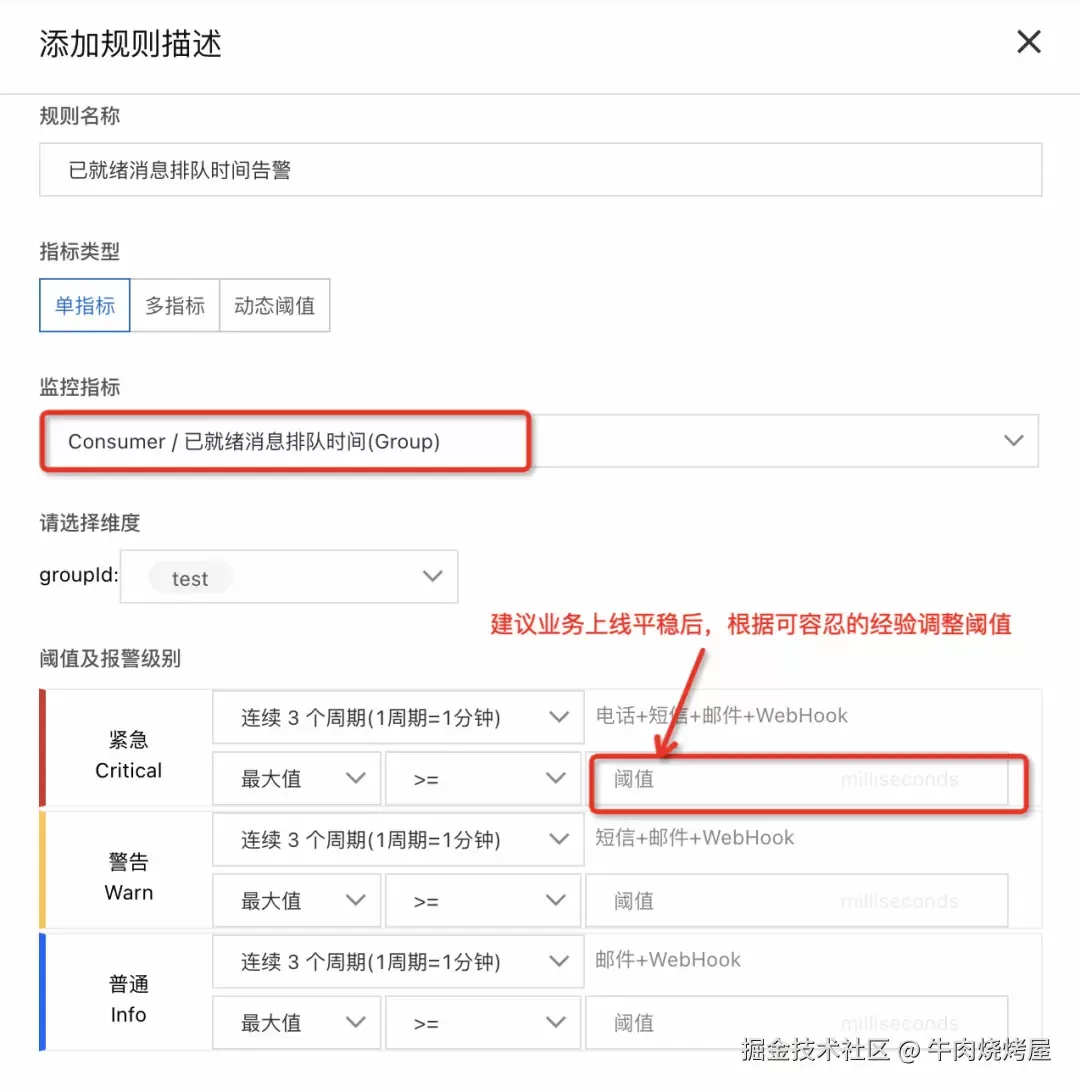
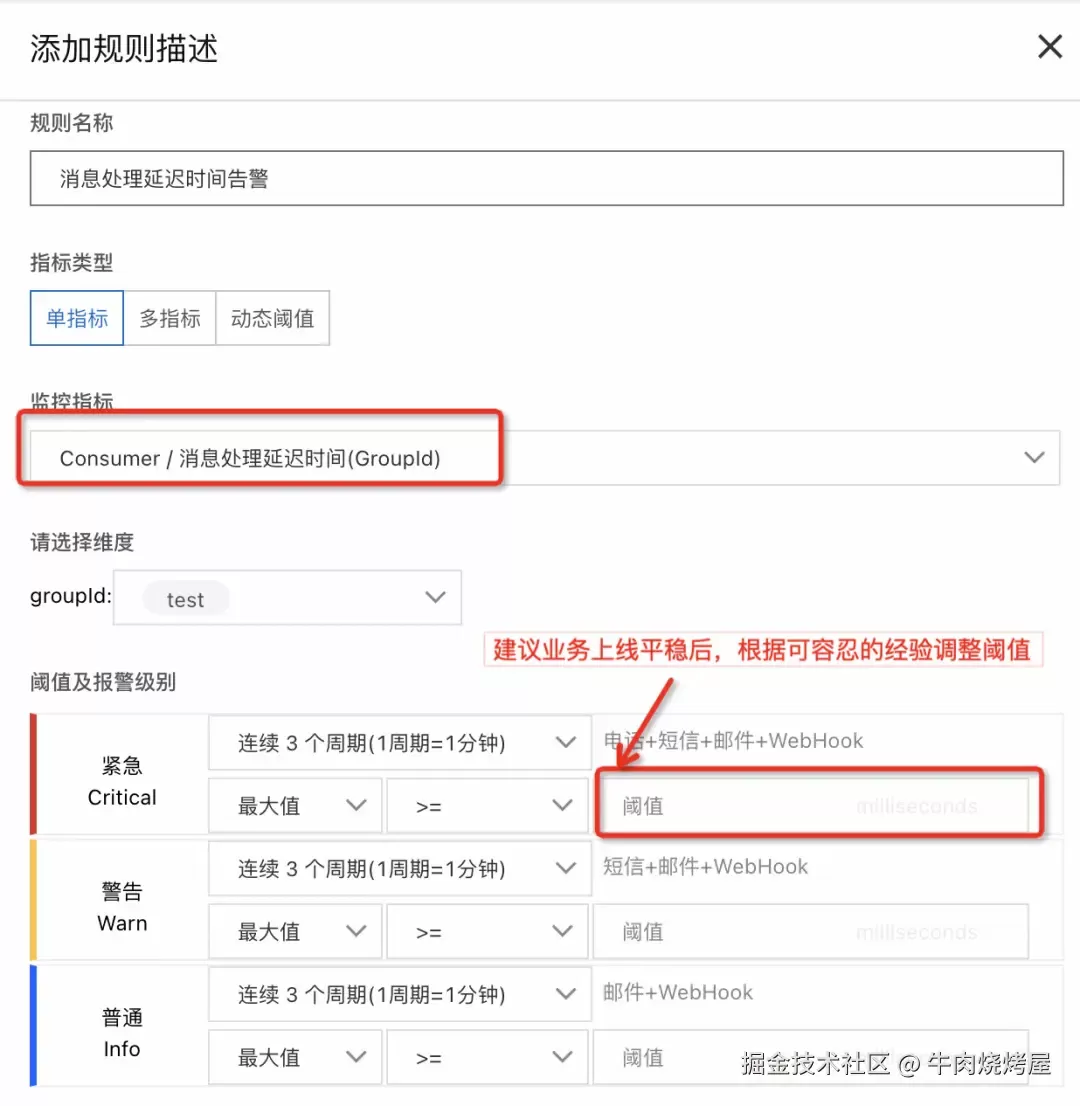
计算方式
定位问题
确定哪一部分出现了「消息堆积」问题?
定位问题的前提是上面的「监控和告警」系统已经搭建,这样才有数据对以下内容判断:
生产端堆积:生产者发送速度 > Broker 处理能力。消息没有被及时发送
生产者发送速率异常飙升(出现了热点,比如某个明星结婚)
网络问题,导致消息发送延迟或失败,导致频繁重试,拉长发送时间
Broker 堆积:Broker 存储能力不足。无法及时接收、存储、投递消息
Broker 写入性能下降(如磁盘满、CPU 过载)
Broker 节点故障或主从同步延迟
Topic 队列数不足,导致消息写入/消费并行度低
消费端堆积:消费者处理速度 < Broker 投递速度。消费没有被及时消费
消费者处理逻辑变慢(如依赖的外部服务延迟增加,如代码内部死锁、外部的 RPC 调用、数据库读写等;没有使用批量消费加快消费速度)
消费者线程池配置不合理、消费者节点太少(资源没给够。比如 99 买了个一年 2c2g 的服务器,拿来消费百万条消息,等服务器过期了也消费不完。本质是资源没给够)
消息处理失败导致重复投递(如代码异常或消息格式错误)
解决消息堆积
如何快速解决线上「消息堆积」问题?
横向扩容:增加消费者实例(出现消息堆积后,第一时间要做的,大部分情况下可以解决问题)
RocketMQ 的「消费者组」支持动态扩缩容,同一消费者组内的多个消费者实例会自动分摊队列的负载
关键条件:队列数量必须 ≥ 消费者实例数。例如,若 Topic 有 16 个队列,最多支持 16 个消费者实例同时消费(在 RocketMQ 4.x 需要保证该条件,而在 RocketMQ 5.x 不需要。具体看下文「补充-消费者负载均衡」)
纵向优化:提升单个消费者的处理能力
调整消费线程数。通过
setConsumeThreadMin和setConsumeThreadMax参数增加并发线程批量消费,聚合写请求,批量写入(具体实现看下文「补充-批量消费」部分)
降低外部服务延迟,比如给 MySQL 加配置,提高对 MySQL 的读写能力
预防消息堆积
为了避免「消息堆积」再次发生,可以这样做:
监控和告警:及时感知「消息堆积」问题
保证消费者拥有满足常规流量的消费能力
确定单点消费者能力和消费者数量,使消费者拥有合理的资源。通过压测单个节点,并逐步调大线程的单个节点的线程数,观测节点的系统指标,得到单个节点最优的消费线程数和消息吞吐量。并根据上下游链路的流量峰值,计算出需要设置的节点数。
节点数 = 流量峰值 / 单节点消息吞吐量提高单点消费性能。可以通过调整消费者线程数、批量消费、排查耗时操作优化代码逻辑、异步处理耗时操作
需要具备应对突发流量的能力。当发现「消息堆积」时,及时对 MQ 和消费者「动态扩容」
发现消息堆积,手动扩容
Kubernetes HPA、云产商自动扩容
资源隔离,风险隔离。不能因为某个业务的「消息对接」导致整个系统不可用
物理隔离。核心业务和非核心业务,分别用各自的 MQ
逻辑隔离。在同一 MQ 中,通过 Namespace、Topic/Queue、Consumer Group 角度进行逻辑隔离
补充
批量消费
通过批量消费,可以降低网络交互次数和带宽消耗,并聚合写操作
比如每次都聚合 10 次写操作,可以将 10 次锁竞争变为 1 次锁竞争,文本传输的数据量也降低至 10%,那性能理论上可以提升 10 倍
比如合并 UPDATE 操作,如下所示:
UPDATE t_video_count SET like_count = like_count + 1 WHERE video_id = 1; ... 8 条 ... UPDATE t_video_count SET like_count = like_count + 1 WHERE video_id = 1; -- 将以上 10 条聚合为 1 条 UPDATE t_video_count SET like_count = like_count + 10 WHERE video_id = 1;
RocketMQ 提供的批处理
消费者可以使用 setConsumeMessageBatchMaxSize和 MessageListenerConcurrently接口实现批量消费
如果我们先开启消费者,再开启生产者。会发现消费者还是一条条拉取,而不是批量拉取,因为消费者并没有等待一会攒数据,刚发来的消息立马就消费完毕了(此时几乎等价 RPC 调用)
所以可以先开启生产者,向 MQ 发送消息,攒一波消息,再开启消费者批量消费。或者生产者采用批量发送,一次性将消息都发送出去
生产者代码:
import org.apache.rocketmq.client.producer.DefaultMQProducer;
import org.apache.rocketmq.client.producer.SendResult;
import org.apache.rocketmq.common.message.Message;
import java.util.ArrayList;
import java.util.List;
public class BatchMessageProducer {
public static void main(String[] args) throws Exception {
DefaultMQProducer producer = new DefaultMQProducer("BatchProducerGroup");
producer.setNamesrvAddr("localhost:9876");
producer.start();
try {
List<Message> messageList = new ArrayList<>();
// 创建多条消息
for (int i = 0; i < 10; i++) {
String content = "Batch message " + i;
Message msg = new Message(
"BatchTopic", // topic
"TagA", // tag
content.getBytes() // 消息体
);
messageList.add(msg);
}
// 发送批量消息
SendResult sendResult = producer.send(messageList);
System.out.printf("Batch messages sent successfully, result: %s%n", sendResult);
} catch (Exception e) {
e.printStackTrace();
} finally {
producer.shutdown();
}
}
}消费者代码:
import org.apache.rocketmq.client.consumer.DefaultMQPushConsumer;
import org.apache.rocketmq.client.consumer.listener.ConsumeConcurrentlyContext;
import org.apache.rocketmq.client.consumer.listener.ConsumeConcurrentlyStatus;
import org.apache.rocketmq.client.consumer.listener.MessageListenerConcurrently;
import org.apache.rocketmq.common.message.MessageExt;
import org.apache.rocketmq.common.consumer.ConsumeFromWhere;
import java.util.List;
public class BatchMessageConsumer {
public static void main(String[] args) throws Exception {
DefaultMQPushConsumer consumer = new DefaultMQPushConsumer("BatchConsumerGroup");
consumer.setNamesrvAddr("localhost:9876");
consumer.setConsumeFromWhere(ConsumeFromWhere.CONSUME_FROM_FIRST_OFFSET);
// 设置每次批量消费的最大消息数量
consumer.setConsumeMessageBatchMaxSize(10);
consumer.subscribe("BatchTopic", "*");
consumer.registerMessageListener(new MessageListenerConcurrently() {
@Override
public ConsumeConcurrentlyStatus consumeMessage(List<MessageExt> msgs,
ConsumeConcurrentlyContext context) {
System.out.printf("Batch consuming %d messages%n", msgs.size());
for (MessageExt msg : msgs) {
String content = new String(msg.getBody());
System.out.printf("Consumed message: %s%n", content);
}
return ConsumeConcurrentlyStatus.CONSUME_SUCCESS;
}
});
consumer.start();
System.out.println("Batch message consumer started.");
}
}在商业版 RocketMQ SDK 中,支持当满足一定的数量或一定的时间时,才拉取消息,解决上面「批量消费但还是一条条拉取」的问题(怎么像打广告呢?)
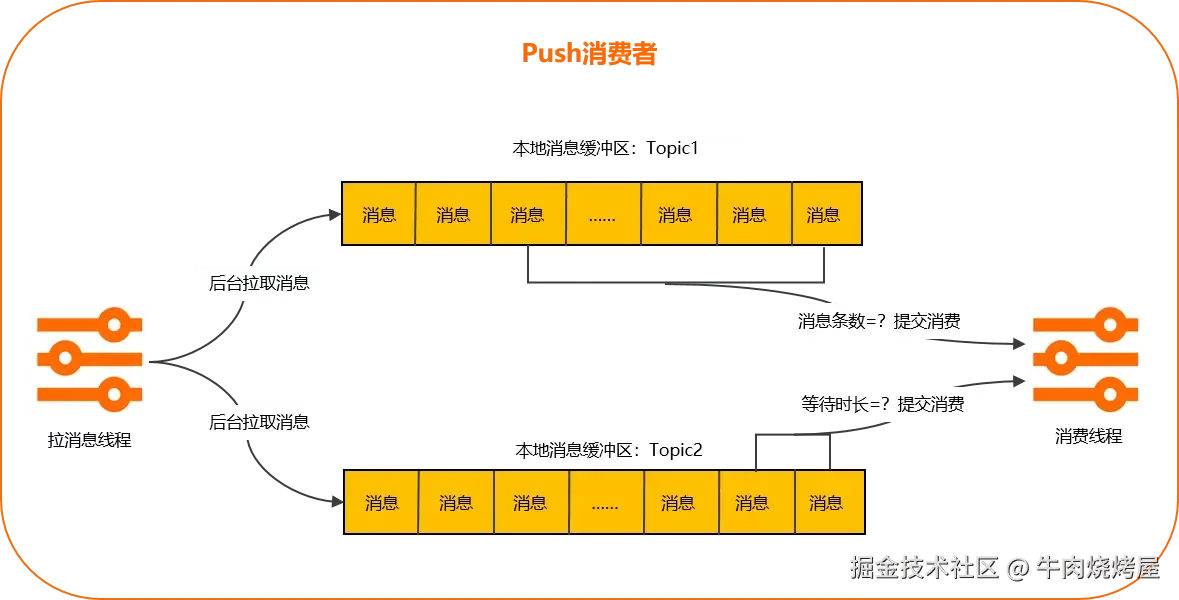
存在问题
重试粒度大。如果批量消费中某条消息处理失败,默认整个批次会重试
消费过于及时,MQ 中没有足够多的消息给消费者批量拉取。不过现在出现了「消息堆积」,这就不是问题了
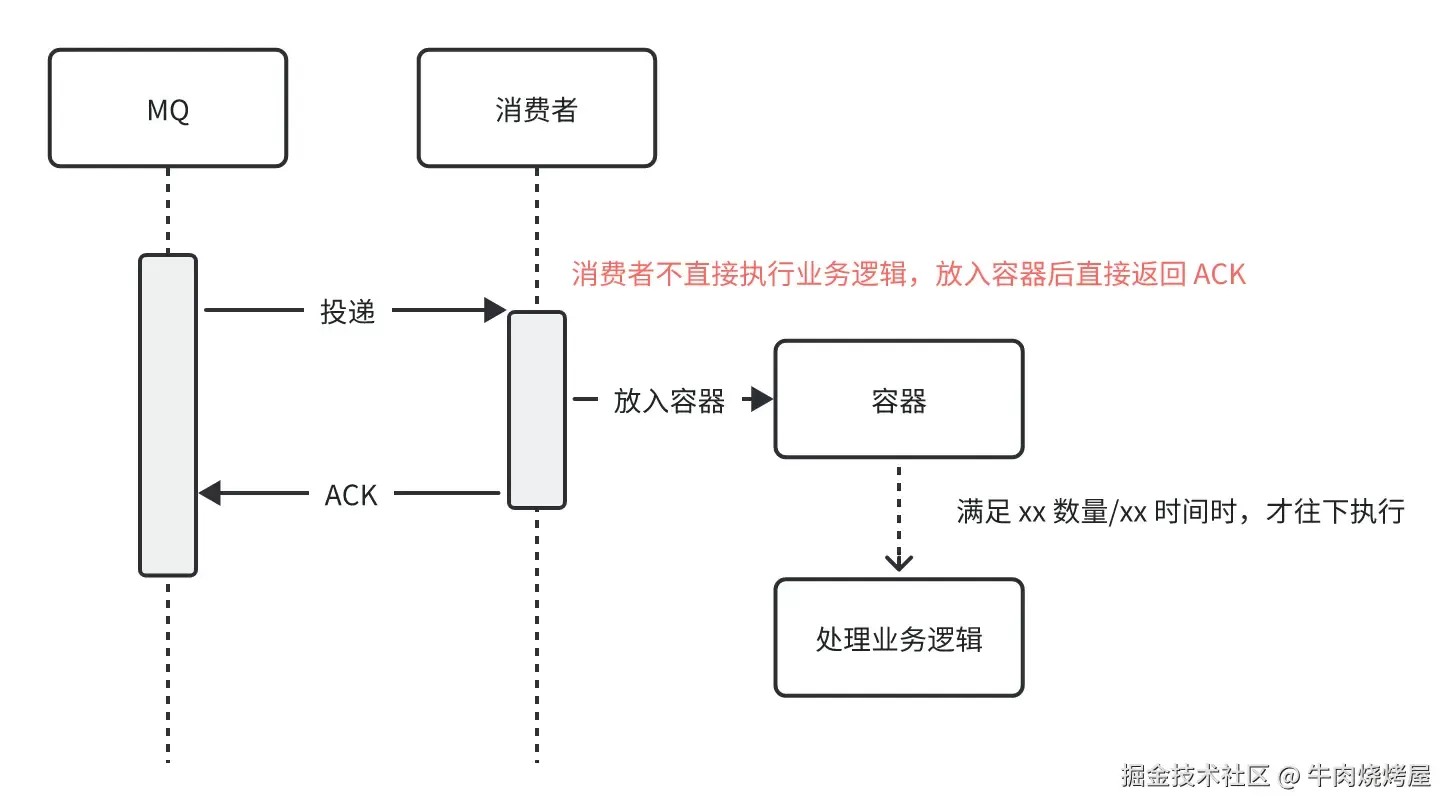
本地缓冲聚合
先把数据往容器里丢,直接 ACK 返回给 MQ。等到满足一定的数量或一定的时间时,再批量消费,执行实际的业务逻辑
这样的好处就是:
将耗时的业务逻辑后置(异步化),尽可能快的 ACK 给 MQ
聚合多个写请求,通过批量写入减少写入次数,提高写入性能
该实现方案不依赖特定的 MQ,具有通用性
传统消费消息:
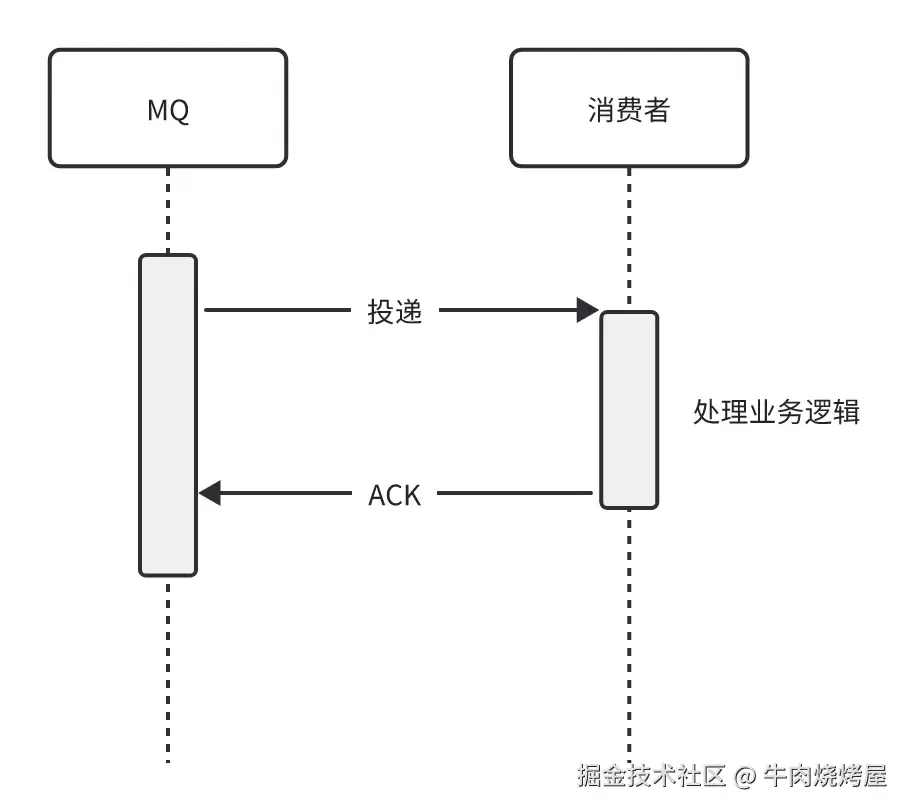
缓冲聚合:
假设现在我们有个视频点赞服务,我们要对点赞计数进行聚合
可以通过快手开源的 BufferTrigger 实现聚合操作
依赖:
<dependency> <groupId>com.github.phantomthief</groupId> <artifactId>buffer-trigger</artifactId> <version>0.2.21</version> </dependency>
生产者代码:
public class LikeMessageProducer {
public static void main(String[] args) throws Exception {
DefaultMQProducer producer = new DefaultMQProducer("LikeProducerGroup");
producer.setNamesrvAddr("localhost:9876");
producer.start();
try {
// 模拟发送多条点赞消息
for (int i = 0; i < 10; i++) {
// 模拟对视频1和视频2的点赞
Long videoId = (i % 2) + 1L;
Message msg = new Message(
"LikeTopic",
"TagA",
videoId.toString().getBytes()
);
producer.sendOneway(msg);
System.out.printf("Sent like message for video %d%n", videoId);
Thread.sleep(10); // 短暂延迟,模拟真实场景
}
} finally {
producer.shutdown();
}
}
}消费者代码:
public class LikeMessageConsumer {
private final DefaultMQPushConsumer consumer;
private final BufferTrigger<LikeOperation> bufferTrigger;
// 点赞操作实体类
private static class LikeOperation {
private final Long videoId;
private final int delta;
public LikeOperation(Long videoId, int delta) {
this.videoId = videoId;
this.delta = delta;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
LikeOperation that = (LikeOperation) o;
return Objects.equals(videoId, that.videoId);
}
@Override
public int hashCode() {
return Objects.hash(videoId);
}
}
public LikeMessageConsumer(String consumerGroup, String namesrvAddr, String topic) {
// 创建正确的 BufferTrigger
this.bufferTrigger = BufferTrigger.<LikeOperation, ConcurrentHashMap<LikeOperation, AtomicInteger>>simple()
.maxBufferCount(100) // 设置最大缓冲数量
.interval(500, TimeUnit.MILLISECONDS) // 设置时间间隔
.setContainer(ConcurrentHashMap::new, (map, operation) -> {
// 使用 computeIfAbsent 确保线程安全地更新计数
map.computeIfAbsent(operation, k -> new AtomicInteger())
.addAndGet(operation.delta);
return true;
})
.consumer(this::processLikeBatch)
.build();
// 创建消费者
this.consumer = new DefaultMQPushConsumer(consumerGroup);
consumer.setNamesrvAddr(namesrvAddr);
consumer.setConsumeFromWhere(ConsumeFromWhere.CONSUME_FROM_FIRST_OFFSET);
try {
consumer.subscribe(topic, "*");
consumer.registerMessageListener(new MessageListenerConcurrently() {
@Override
public ConsumeConcurrentlyStatus consumeMessage(List<MessageExt> msgs,
ConsumeConcurrentlyContext context) {
for (MessageExt msg : msgs) {
try {
// 假设消息体就是视频ID
Long videoId = Long.parseLong(new String(msg.getBody()));
// 将消息放入 BufferTrigger
bufferTrigger.enqueue(new LikeOperation(videoId, 1));
} catch (Exception e) {
System.err.println("Error processing message: " + e.getMessage());
}
}
return ConsumeConcurrentlyStatus.CONSUME_SUCCESS;
}
});
} catch (Exception e) {
throw new RuntimeException("Failed to initialize consumer", e);
}
}
// 批量处理点赞
private void processLikeBatch(ConcurrentHashMap<LikeOperation, AtomicInteger> aggregatedMap) {
if (aggregatedMap.isEmpty()) {
return;
}
// 处理聚合后的结果
for (Map.Entry<LikeOperation, AtomicInteger> entry : aggregatedMap.entrySet()) {
LikeOperation operation = entry.getKey();
int totalDelta = entry.getValue().get();
System.out.printf("[%s] 执行聚合更新: UPDATE t_video_count SET like_count = like_count + %d WHERE video_id = %d%n",
getCurrentTime(), totalDelta, operation.videoId);
// TODO: 在这里添加实际的数据库更新代码
// jdbcTemplate.update(
// "UPDATE t_video_count SET like_count = like_count + ? WHERE video_id = ?",
// totalDelta, operation.videoId
// );
}
}
private String getCurrentTime() {
return java.time.LocalDateTime.now().format(java.time.format.DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss"));
}
public void start() throws Exception {
consumer.start();
System.out.println("Consumer started.");
}
public void shutdown() {
bufferTrigger.close();
consumer.shutdown();
}
public static void main(String[] args) throws Exception {
LikeMessageConsumer consumer = new LikeMessageConsumer(
"LikeConsumerGroup",
"localhost:9876",
"LikeTopic"
);
consumer.start();
Runtime.getRuntime().addShutdownHook(new Thread(() -> {
consumer.shutdown();
System.out.println("Consumer has been shutdown.");
}));
}
}存在问题
一致性问题。如果聚合时宕机,内存的数据都将丢失。因为消息已经 ACK,MQ 不会重新投递。需要考虑异常崩溃时的一致性问题。常见的一致性解决方案就是使用定时任务对账
额外的写入延迟,适用于对延迟不敏感的场景
消费者负载均衡
添加节点并不是在所有情况下,都一定能提高消费的吞吐量的,需要考虑「消费者负载均衡」的影响
队列粒度
在 RocketMQ 4.x 中,默认采用「队列粒度」负载均衡
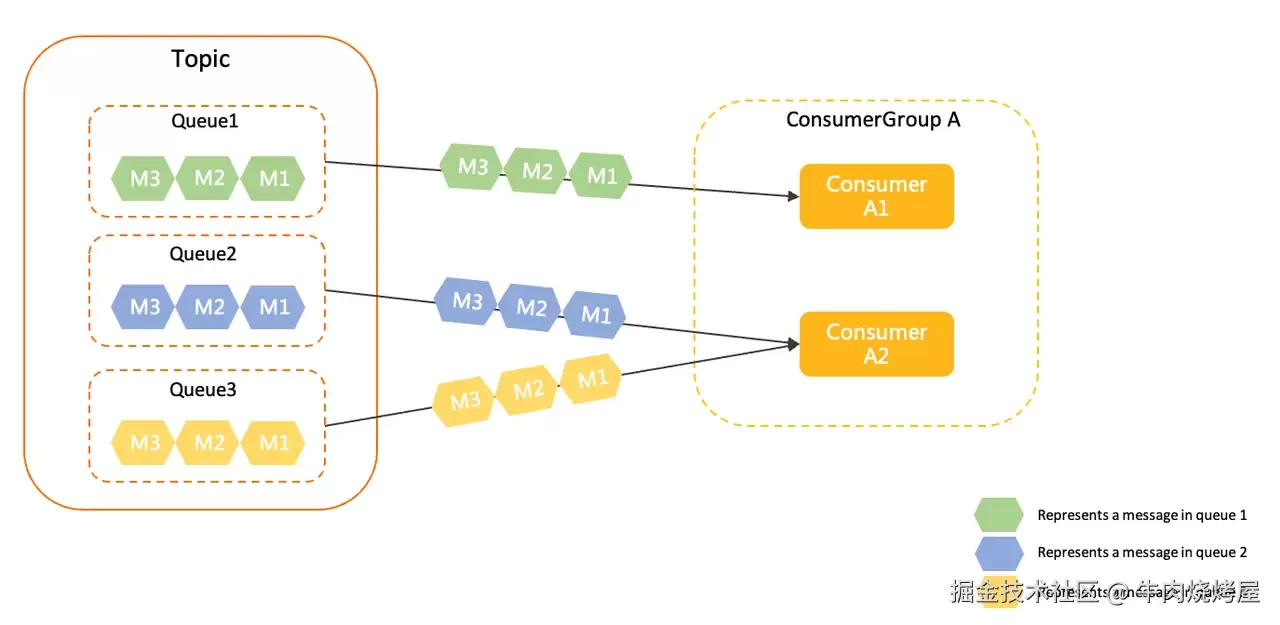
每个队列仅被一个消费者消费,队列和消费者的关系为多对一
如上图所示,主题中的三个队列 Queue1、Queue2、Queue3 被分配给消费者分组中的两个消费者,每个队列只能分配给一个消费者消费。图中由于队列数 > 消费者数,因此,消费者 A2 被分配了两个队列。若队列数 < 消费者数量,可能会出现部分消费者无绑定队列的情况
这也就导致了当队列数 < 消费者数量时,继续添加消费者节点无法提高消费的吞吐量
消息粒度
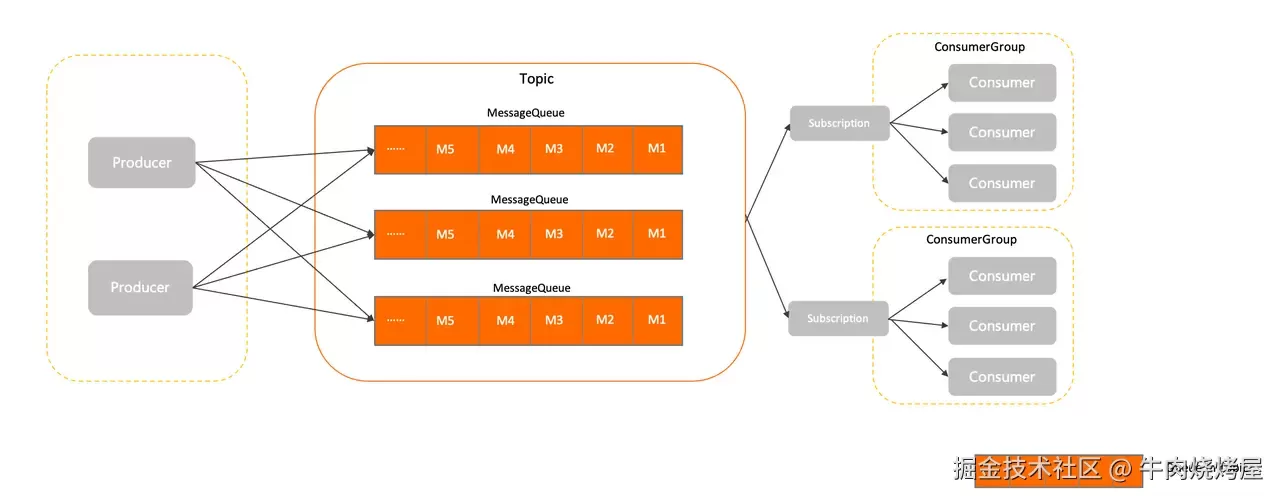
在 RocketMQ 5.x 中,默认采用「消息粒度」负载均衡
相对于队列粒度负载均衡策略,消息粒度负载均衡策略有以下特点:
消费分摊更均衡:对于传统队列级的负载均衡策略,如果队列数量和消费者数量不均衡,则可能会出现部分消费者空闲,或部分消费者处理过多消息的情况。消息粒度负载均衡策略无需关注消费者和队列的相对数量,能够更均匀地分摊消息。
对非对等消费者更友好:在线上生产环境中,由于网络机房分区延迟、消费者物理资源规格不一致等原因,消费者的处理能力可能会不一致,如果按照队列分配消息,则可能出现部分消费者消息堆积、部分消费者空闲的情况。消息粒度负载均衡策略按需分配,消费者处理任务更均衡。
队列分配运维更方便:传统基于绑定队列的负载均衡策略必须保证队列数量大于等于消费者数量,以免产生部分消费者获取不到队列出现空转的情况,而消息粒度负载均衡策略则无需关注队列数。
即,不需要保证队列数 >= 消费者数量,它们的数量对应关系是多对多的,可以是任意的相对数量。所以,继续添加消费者节点可以继续提高消费的吞吐量
结语
通过监控和告警、定位、解决、预防,从而
为了尽可能降低「消息堆积」带来的危害,可以执行以下步骤:
监控和告警:及时发现「消息堆积」问题
定位:排查生产者、MQ、消费者
解决:水平扩容、纵向优化
预防:监控和告警、提高消费能力、动态扩容、风险隔离
还有其他解决方案:
有限的重试次数,多次失败后会自动放入「死信队列」中。避免无限次重试导致“队头阻塞”
先把消息写入到数据库,短暂解决「消息堆积」问题,但是实现很麻烦,而且一会可能又堆积了
舍弃不重要的消息。但是又有多少消息是不重要的呢?无法根治「消息堆积」问题
最直接的解决方案,还是提高下游的消费能力,不过需要考虑「消费者负载均衡」的影响,不是所有情况都是只加节点就能解决的
当线上出现了「消息堆积」问题,可以从侧面反映出当前业务场景的流量是比较大的。那么在高并发的环境下,如何保证 MQ 的稳定性?可以在评论区中,谈谈你的看法!
